

PyTorch established a simple a consistent toolset for building training pipelines. The most common scenarios can be handled with two utilities: the Dataset class and the DataLoader class. I wrote about them in my previous article. I've noticed some practical limitations of this approach and I show how to resolve them in this article.
tl;dr - check out the last but one snippet for full implementation
Motivation
The Dataset class realize the concept of a map-style datasets. In its simplest form it can be reduced to a list of files and a function that lazily loads them. There is a strong assumption that each file can be transformed into a fixed number of equally shaped tensors. This is usually true. For example, in the classification tasks every file is transformed into a tuple of an image tensor and a scalar - (image, label).
What if a single file contain multiple training entities? When we train an object detection model there are likely multiple objects on a single image. On the example image below there are just two cats but we can't expect the same quantity on every photo. A map-style dataset would enable us to extract only a fixed number crops. (trivium 1)
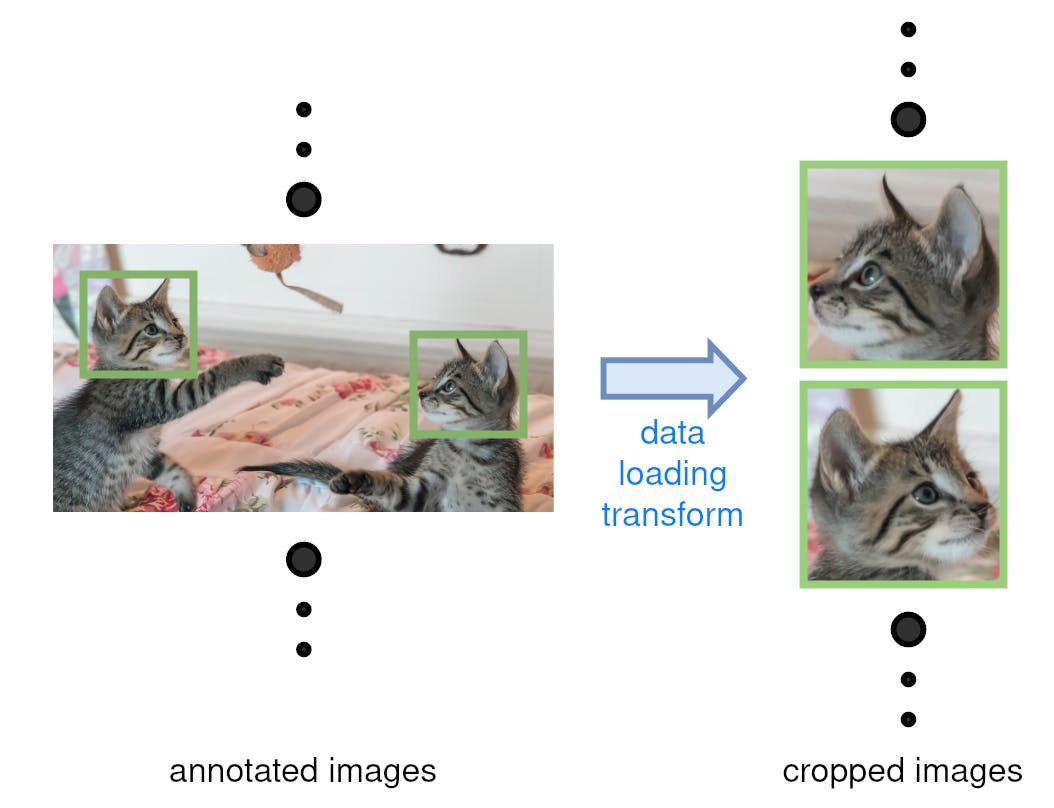
Alternatively, what if a file does not contain any entities? Such files probably shouldn't be included in the first place, but it's difficult to filter out all malicious cases. Especially, when the datasets are constantly being updated by different members of the team. We'd rather not stop an expensive and time-consuming training due to a single erroneous annotation. It's better to gracefully ignore it.
In such scenarios it's worth taking a look at the iterable-style datasets. The idea is simple, given some knowledge about regular Python generators. Yet it is difficult to properly combine them with the DataLoader, due to the properties of its parallelization mechanism. In this article, I show how to parallelize data loading using IterableDataset with DataLoader and propose FlatMapDataset, which makes this process significantly easier.
IterableDataset
Let's say we have a list of image files with text characters annotations. For each character there is an annotation denoting it's bounding box (much like in the cats dataset example). It is important that we can't load all images at once before the training, because they wouldn't fit the memory (trivium 1). Let's consider a following, faulty implementation:
class CharDataset(torch.utils.data.IterableDataset):
def __init__(self, files):
super().__init__()
self.files = files
def __iter__(self):
for file in self.files:
image, boxes = load_example(file)
for box in boxes:
yield crop_image(image, box)
If we assume that all boxes have the same size (or resize them to some arbitrary uniform size) we can now pass an instance of this class to a DataLoader and make it produce batches of cropped character images. The batch concatenation (one of the main features of the DataLoader) is working correctly.
dataset = CharDataset(files_list)
data_loader = DataLoader(dataset, batch_size=3, num_workers=0)
# data_loader can be iterated to receive triples of images
What about the parallelization? The example above would work only because we set the number of worker threads to 0, i.e. everything is executed in the main thread (btw. 0 is the default). For values greater than 1 the behavior would be somewhat strange. If the number of workers was set to N every batch would be likely repeated N times.
It's important to understand the parallelization mechanism. Every worker (i.e. process) receives an exact copy of the dataset and starts to repeatedly fetch new examples. Here is a hypothetical implementation of the worker thread's logic:
# dataset_copy - a copy of the dataset instance
# collate_fn - a function that transforms lists of examples into batches
# (see DataLoader docs or my previous article for details)
examples_iterator = iter(dataset_copy)
while True:
examples_list = [next(examples_iterator) for _ in range(batch_size)]
batch = collate_fn(examples_list)
push_to_some_global_queue(batch)
This pseudocode would look a bit differently for map-style datasets. In an iterable-style dataset, the workers do not coordinate to read different parts of the dataset by default (trivium 2). It must be handled manually in the IterableDataset's __iter__ method.
Worker Info
For each worker process, PyTorch defines a global structure which allows to coordinate the data loading process. It can be accessed with:
worker_info = torch.utils.data.get_worker_info()
The most important fields of the returned structure are self-explanatory num_workers and id which is a unique integer identifier of the worker.
When there is an underlying list of objects, there is a generic solution of assigning a different set of indices to each worker. This is the case for the CharDataset example above. Given a list of size M, which represent all examples in the dataset, every worker should produce exactly K = M / num_workers examples. In that case the first worker would produce examples from 0 to K - 1, the second from K to 2 * K - 1 and so on.
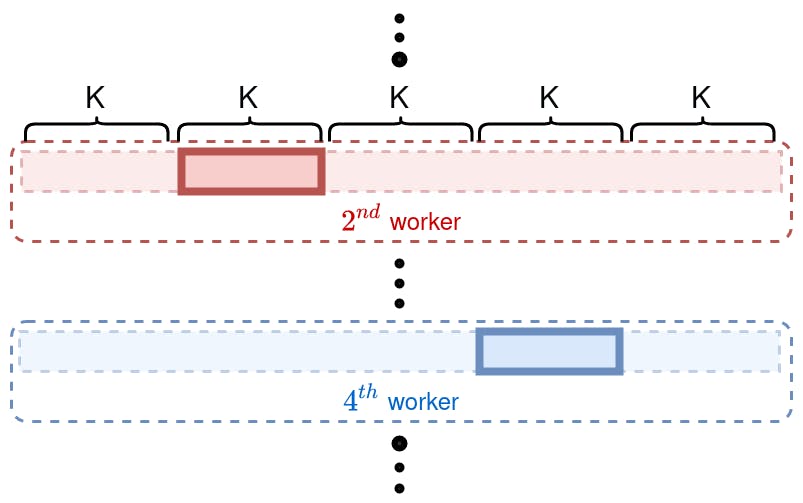
Each worker receives a copy of the entire dataset so it needs to manually restrict itself to a unique subset, as shown on the diagram above.
def __iter__(self):
worker_files = self.files
worker_info = torch.utils.data.get_worker_info()
if worker_info:
k = len(self.files) / worker_info.num_workers
worker_first_index = worker_info.id * k
next_worker_first_index = worker_first_index + k
worker_files = self.files[worker_first_index: next_worker_first_index]
for file in worker_files:
image, boxes = load_example(file)
for box in boxes:
yield crop_image(image, box)
The core loops is almost unchanged, but we had to add a lot of boilerplate at the beginning. This looks discouraging, but the pattern seem repeatable, so it can be replaced with some more generic concept - FlatMapDataset.
FlatMapDataset
The simplest approach to create a more generic solution is to take the improved version of the CharDataset example and replace the non-generic part with a user-provided function that maps each loaded entity into a sequence of the actual training examples:
class FlatMapDataset(torch.utils.data.IterableDataset):
def __init__(self, entities: List, fn: Callable):
super().__init__()
self.entities = entities
self.fn = fn
def __iter__(self):
worker_entities = self.entities
worker_info = torch.utils.data.get_worker_info()
if worker_info:
k = len(self.entities) / worker_info.num_workers
worker_first_index = worker_info.id * k
next_worker_first_index = worker_first_index + k
worker_entities = self.entities[worker_first_index: next_worker_first_index]
for entity in worker_entities:
for example in self.fn(entity):
yield example
We condition on worker_info, because it equals None if the code is run from the main thread. This happens when we configure the DataLoader to use 0 workers or iterate the dataset directly. In such case, we use the whole list. We can now reproduce the CharBased dataset with a simple function that maps a file path to the sequence of cropped images denoted by the annotated bounding boxes:
def read_examples(file):
image, boxes = load_example(file)
for box in boxes:
yield crop_image(image, box)
dataset = FlatMapDataset(files_list, read_examples)
Looks much more convenient already! Note that if I was troubled by inconsistent annotations, which would cause my reading logic to fail, I could simply enclose the read_examples body with a try-catch block and not yield anything:
def read_examples(file):
try:
image, boxes = load_example(file)
for box in boxes:
yield crop_image(image, box)
except Exception as e:
print(e) # please, use an actual logger for such core utilities
Note that the class's name comes from a higher-order flatmap function that is a core concept in the functional programming. Here is some concise explanation for Java (unfortunately there is no built-in flatmap in Python):
Accepting map-style datasets
Some of the utilities listed in the PyTorch documentation follow a pattern of a function that transform an existing dataset object in to a new one. For example there is a ConcatDataset class which wraps a list of existing Dataset objects and represent their concatenation. There is an analogous ChainDataset class which wraps IterableDatasets. It's important to note that each utility works only on a specific style of dataset.
In our case, we would like to transform a map-style Dataset into an iterable-style IterableDataset. That enables the best features of both, e.g. shuffling of the map-style dataset and error suppression of the iterable-style dataset.
A map-style dataset doesn't behave exactly like a list - it doesn't support slicing. The workaround is to slice a list of all possible indices. The user-provided function will now map the examples produced by the original dataset into a sequence of transformed examples:
class FlatMapDataset(torch.utils.data.IterableDataset):
def __init__(self, source: Dataset, fn: Callable):
super().__init__()
self.source = source
self.fn = fn
def __iter__(self):
indices = list(range(len(self.source)))
worker_info = torch.utils.data.get_worker_info()
if worker_info:
k = len(self.source) / worker_info.num_workers
worker_first_index = worker_info.id * k
next_worker_first_index = worker_first_index + k
indices = indices[worker_first_index: next_worker_first_index]
for index in indices:
for example in self.fn(self.source[index]):
yield example
Let's assume that we already have a Dataset specialization that returns a pair of (image array, list of bounding boxes). Note that this formulation is technically correct, but it couldn't be directly used with the DataLoader class. The default batch construction mechanism is not able to deal with a list of varying size (btw. it can be overriden). FlatMapDataset allows us to implement a concise flow:
source_dataset = SourceDataset()
source_train, source_valid = torch.utils.data.random_split(
source_dataset, [9000, 1000])
def crop_boxes(example):
image, boxes = example
for box in boxes:
yield crop_image(image, box)
train_dataset = FlatMapDataset(source_train, crop_boxes)
data_loader = DataLoader(train_dataset)
First we create the source dataset that produce the input tuples. It's __getitem__ method simply calls the load_example function for each of the files. Then we perform a train-validation split. Note that this is possible only for a map-style dataset. The construction of FlatMapDataset and DataLoader is straightforward. We end up with an object that can be iterated to obtain batches of cropped images (e.g. single characters obtained from photos of entire documents or cat heads like on the first diagram).
Exceptions
I've omitted the try-catch clause in the last example, because it wouldn't be fully effective. While we would catch the errors in the crop_boxes body, we could still encounter the ones occurring in the SourceDataset.__getitem__. A malformed annotation file would still crash the training.
One way to approach this issue is to place the try-catch clause in the FlatMapDataset directly:
class FlatMapDataset(IterableDataset):
def __init__(self, source, fn: Callable):
self.source = source
self.fn = fn
def __iter__(self):
indices = list(range(len(self.source)))
worker_info = torch.utils.data.get_worker_info()
if worker_info:
k = len(self.source) / worker_info.num_workers
worker_first_index = worker_info.id * k
next_worker_first_index = worker_first_index + k
indices = indices[worker_first_index: next_worker_first_index]
for index in indices:
try:
for ex in self.fn(self.source[index]):
yield ex
except Exception as e:
print(e)
pass
This may be somewhat controversial, because it's not necessarily desirable to dismiss all errors. If you are very confident about your dataset, or if missing any single datapoint makes the whole training pointless, you should stick to the previous snippet (trivium 3).
Now, let's say we already have a regular Dataset specialization, that we've used for ages, but we occasionally struggle with erroneous examples. You can use FlatMapDataset with a simple identity-like lambda to create a safe wrapper:
old_dataset = OldDataset()
safe_dataset = FlatMapDataset(old_dataset, lambda x: [x])
safe_data_loader = DataLoader(safe_dataset)
Summary
FlatMapDataset is extremely useful because it enables the features of both map-style and iterable-style datasets. The idea is to first create a map-style Dataset specialization and transform it into an iterable-style IterableDataset using FlatMapDataset. The first form allows for all operations that could require a random access to the elements to a collection such as indexing and shuffling. The second one enables us to realize one-to-many mapping, which includes a possibility to skip some examples.
Unfortunately, at this time, PyTorch offer only few data utilities. The biggest disappointment is that some features of the DataLoader (e.g. shuffle, samplers) work only for the map-style datasets. It is possible to achieve the same effects using transformations applied to a Dataset before using it to construct a DataLoader. Sadly, even those utilities hasn't been created yet. If you'd like to use any kind of iterable-style datasets (including FlatMapDataset), you'd likely need to prepare some of those utilities yourself. Let's hope that it will change in the future.
In its current form the class accepts map-style Datasets and all other list-like objects that support integer indexing. It would be perhaps useful to also support iterables such as IterableDataset (technically FlatMapDataset is still an IterableDataset). I gave it some thought, but I didn't come with an elegant solution. It would be necessary to ensure that the workload distribution happens in only one of them.
Trivia
- Most of the time the limitations resolved by the proposed solution can be also resolved with some expensive pre-processing. It is often a good idea, however, it is not always optimal, e.g. if the original dataset is frequently updated or if a single image contains hundreds of objects.
- In case of the map-style datasets the
DataLoaderknows that there is a range of valid indices (namely all integers from 0 to the dataset's length). It can split this range intoNequal parts and pass each of them to one of the workers. I actually used the same properties in theFlatMapDatasetimplementation. - Another graceful way of handling erroneous examples could be to simply establish a protocol, where the
SourceDatasetmay returnNonefrom its__getitem__method. Then, the user could simply check forNonein the mapping/transform function and return an empty sequence / yield nothing.